
A brief primer
Please save yourself from agony, developer cycles, data breaches, and future problems with a simple design change.
Rock star junior engineer, Amro, needs to grab customer records held on data tier and process them for a OLTP transactional customer-facing web application. To meet a quick deadline, Amro immediately proceeds to grab raw data from the databases and introduce application-layer side stages – validation, filtering, and transformations. Amro starts writing additional lines of code and pushes out a quick PR ( pull request ) for his feature.
But Amro’s senior engineer, Delia, foresees problems with this approach. She thinks pre-emptively of scenarios that Amro might not have thought about either due to a lack of domain expertise or experience working across tech companies. Delia thinks about problems that could arise with pushing out features immediately, as listed below :
- Less code is better code : Writing additional code always means the following – more locations for bugs, more breaking locations, and writing more unit tests or end-to-end tests. The more code at data tier, the less code at source tier : source code, unit tests, or end-to-end tests. That means fewer bugs.
- Minimize network traffic : Immediately grabbing raw data introduces large payloads under network transmission. This becomes especially problematic on scale-out scenarios reaching one million plus events. Can we minimize the volume of data being transferred? Let’s pre-empt and make huge cost savings and optimizations by passing 1 KB in place of 1 TB per day.
- Leverage database capabilities : SQL-esque databases have been around the block since the 1970s; NoSQL since the early 2000s. Thousands of database engineers, designers, and developers have hammered out and fine-tuned their offerings with highly-optimized capabilties spanning querying, filter, retrieval, fuzzy or exact search, and so on. SQL queries naturally get optimized by a SQL query planner running under-the-hood. Database compilers translate human-written queries to an optimized instruction set.
- Minimize cache or memory footprint : Retrieving raw payloads means having to store large chunks of information at application layer. This can lead to performance degradations or a lack of space at disk/cache/memory layers for more exigent, important processes. Let’s optimize memory ahead of time.
- Less dev work : We can remove stages for input validation, sanitization, transformations, of filters at application layer if we push more of that work at the data tier. We have fewer blocks of code or modules to write.

Delia returns back to Amro with a better proposition and highlights better changes to the system architecture. She shows a visual aid to Amro with fewer sequence steps. The design evolution looks better.
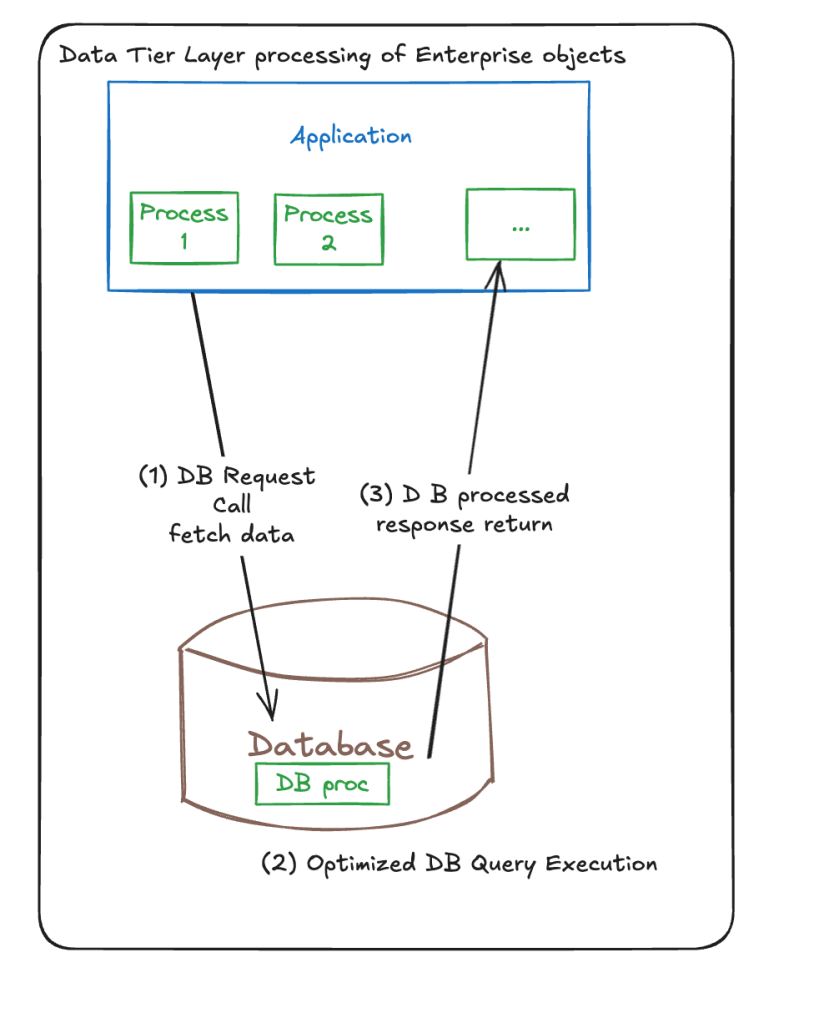
But wait, there’s gotta be reasons for app-side processing!!! What are they?
Ok ok, I hear you out. Application-layer processing still has merits, even if it entails extra network hops and extra LOC ( Lines of Code ) for source code and unit testing code. Let’s engage in multi-perspective thinking and cover cases when it’s needed.
- Security constraints : Suppose you work for a financial company whose customer financial records are encrypted objects – decryption is restricted to application-layer code ( to pre-empt data breaches ). Enterprise justifications force application-side processing.
- Your application needs a complete view of data : It’s rare, but it happens. Engineering requirements typically involve grabbing heavily-filtered subsets of rows or columns. But maybe requirements mandate grabbing all data for third-party auditing or comprehensive reports generation.
- Datatier capabilities are lacking : I briefly touched on this earlier, but databases like SQL have existed since the 1970s – thousands of individuals poured their talents and efforts to making optimized databases for handling multiple tasks. But hey, maybe you can’t execute a very specific fuzzy text search, RegEx expression, or complex filtering on application side. Or data needs to be reformatted ( e.g. conversion of a list of tuples to a key-value dictionary ).
- Application layer business logic complexity : This touches on point #3, but some companies execute complex enterprise logic on their business objects. And current research into data solutions – SQL or noSQL – don’t show good offerings. In that case, we’ll have to create objects ( in OOP ) or other abstractions at application layer to handle our requirements.
Links
1. https://excalidraw.com/#json=TEIM8-FnZ5RFeIcgECZ-P,zBHoGfCWw11AzZo3fBI7Xw
Kudos to Excalidraw for enabling quickly making software engineering figures

Leave a comment