
There’s a storm brewing!!! … some old time sailor ( he’s right )
Hi all!
I want to introduce another good TOTW ( tip-of-the-week ) in codebase architecture. This scenario mirrors one that I encountered at work – I engaged in multiple back-and-forth conversations with other senior engineers on my team, so I think there’s sagacity to imparted lessons.
Alright, well, what’s the story?
There’s an burgeoning internal data governance and controls platform in a company – internal teams ( the customers ) onboarding to this new platform. The reasons are a plenty – there’s to many individualized solutions for multiple teams, the solutions are tightly-coupled, and they’re inefficient. The new controls platform intends to centralize a solution whose functionalities are just as good – or better – than what’s pre-existing.
Initially, the central platform starts out more like one of these individualized platforms ; it’s tightly-coupled to a dedicated team and its single business workflow ( which I’ll call t1_workflow`Type1 ).
Freshly-minted senior engineer Bradbury, faced with some of his first design challenges, gets thrown “into the deep end”. The platform and the product are maturing these next couple months. This means the onboarding of additional teams with their own workflows across multiple quarters. This means that the codebase is slowly transitioning from a monolithic application to a microservice-based architecture, and Bradbury needs to figure out how to organizing the services ahead of time.
And it’s going to be challenging? Why?
In theory, if all information is known, all invariants are established, and the systems are well-contained and small in scope, it’s easy to quickly brainstorm and conjure up a solution.
But there’s a lot that Bradbury doesn’t know. Which he can know, if and only if he collaborates and engages in discussions with multiple parties at his company. His product owners coordinate feature planning and roadmaps with each customer ; his management and leadership communicates pressing deliverables and deadlines with the highest priority ; his team’s engineering talent- staff, seniors, and juniors – know microservices, architectural patterns, and specific codebase sections better than he does. Bradbury needs to combine and synthesize knowledge captured across working silos into a cohesive and coherent understanding.
What’s the first thing Bradbury should do? He should avoid coding and architecture, and should first gather business requirements ( what are they? what’s the most important? and in which order? ). Let’s analyze a couple of them
Business Requirements Ordering :
a. Add t1_workflowType2 ( quarter_1 )
b. Add t2_workflowType1, t2_workflowType2, and t2_workflowType3 ( quarter_1 )
c. Add t3_workflowType1, t3_workflowType2 ( quarter_2 )
d. Add t4_workflowType1, t4_workflowType2 , t4_workflowType3 ( quarter_2 )
And there’s future quarters with more unknowns ( what’s happening in quarter’s 3 and 4 of the same year ? Do we know how many more teams and workflows we’re adding )? We don’t know. The engineers don’t know. Product owners don’t. Leadership & management doesn’t know. Not due to a lack of intellectual capability, but rather, the future is hard to predict. A stakeholder who promised to onboard three workflows can circle back six months later and say that they want to onboard a subset – or gasp, even none – of them.
To further add complexity, some workflows bear striking similarities, and others, major differences. Some workflows are so similar as to entail a singular if-else conditional delta ( e.g. t2_workflowType1 and t1_workflowType2 are pragmatically the same ). As for other workflows, they’re completely different functionality – we need to literally write a new function to handle the edge case scenarios.
There’s a lot of good, clarifying questions we need to ask ourselves.
The Clarifying Questions
- How do we best prepare for an unknown future?
- How do we isolate failures and make it easy to introduce a logging posture to debug issues across teams and workflows?
- How do we build solutions with plug-and-play customizability, so that if I need to quickly modify a workflow across teams – or single-team specific – I can do so with alacrity?
- Can I identify the path of least resistance and minimal developmental effort?
- What coding style would be the easiest for other engineers – not just myself – to read and to maintain?
There’s a storm brewing.
The naive approach :
The naive approach is to introduce all workflow and all team logic into the same functionality. If there’s a pre-existing function ( let’s name it t1_workflowType1() ), we can build out a rules engine esque module and stuff in nested if-else logical statements for discrepancies encountered on each workflow type and team type. This solution is valid in the case of a MVP ( minimal viable product ), where the workflows are mostly similar to one another and limited in number. But there’s drawbacks when we encountered scalability concerns :
The drawbacks
- Collisions of Responsibilities – the same method handles to many responsibilities across teams and workflows.
- Hard to feature test – writing tests are going to be hard ; every time I write a test, I have to make sure it passes conditions across multiple layers of business abstractions
- Hard to maintain and to read – such a function would be ginormous. Multiple nested if-else or switch-case statements would pepper the code.
Enter the world of “Plug-and-Play”
Before engineer Bradbury sets forth his long-term vision, senior engineer Josh arranges a couple of design discussions. Josh shares his technical disagreements with Bradbury, using the visual aids of the product roadmap – created by collaborations of his product owners with leadership and management – to effectively communicate his points.
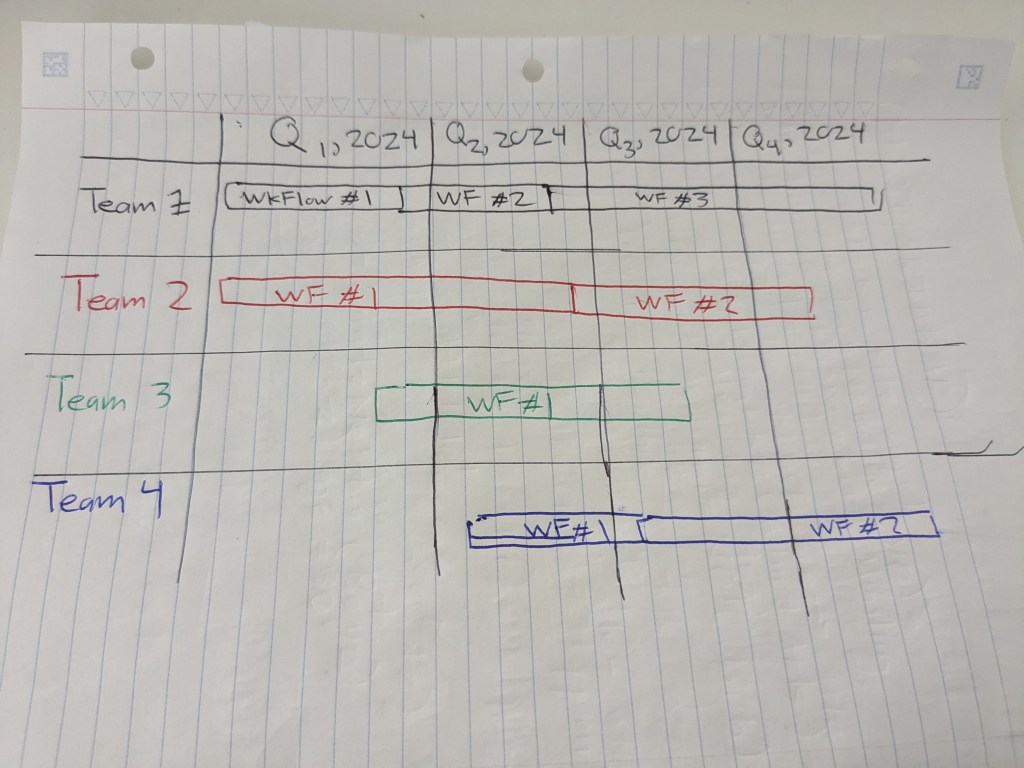
Josh avoids engaging in disparagements of Bradbury’s perspective. Instead, Josh considers Bradbury’s input with seriousness, because our titular character recognizes that he may have been thinking to much of a short-term deliverable due to a lack of visibility of long-term planning roadmaps.
The design discussions help – Bradbury shifts from disagreements to shared consensus; they both research plug-and-play solutions. This solution entails functional decomposition at the granularity of teams and workflows . The solution facilitates the quick onboarding and offboarding of business needs. But what scenarios could occur for each team ( in the case, the stakeholder )?
- Onboarding isn’t needed.
- Onboarding needs to be delayed ( by a few weeks or a few quarters )
- The order of onboarding of workflows needs to change
Benefits of “Plug-and-Play” Solutions
- Singular Responsibility Pattern – by decomposing teams and their workflows into separate functions, we can quickly isolate functionality at the highest level of granularity. This makes it easy to debug and understand the code.
- Testing ease – It’s not just coding we need to think about ; I need to build unit tests and end-to-end tests across each business use case. Introducing isolation levels makes it easy for me to test out and validate a team’s onboarding in a sequential manner ( e.g. I can assert and say that I have a subset of workflows or 100% of workflows working for teams 1 and teams 2, even if teams 3 and 4 are still onboarding ).
- Customization ease – suppose a team needs changes to be made to a workflow ( e.g. legal and compliance comes in and mandates the masking of PII ). In this case, I can quickly dive into a piece of code and introduce masking logic or encryption logic on payloads.
- Business Requirements Flexibility – Suppose months later, a team needs to offboard ( some or all ) of its workflows. Or a team suddenly needs to onboard. Without having to make possibly destructive changes to a single method, we can quickly add function calls or remove function calls to isolated pieces of code, introducing a couple of comments along the way. Or suppose two teams are pending approval for onboarding – I can prioritize and shift developmental efforts to support the current use cases

Leave a comment