
( and please don’t let the fear-mongering of the world migrating to streaming get to you )
Building Automation – a Primer
Hi all,
I’ve been working hard on a ETL-esque project at Geico to set up the internal plumbing, the infrastructure, and the business workflows to automate and execute the following :
Step #1 ( SCAN ) : Scan a data source and populate a local table with records of each scan
Step #2 ( EXPORT ) : Trigger an export of the data to its destination
In today’s current state, we’re automatically scan data sources and populate our table of records, but, we manually trigger endpoints to export.
But tomorrow’s world. Well that needs to look different? The scan and the export needs to be automated. Not only because end customers need to see their results as soon as possible, but also because we can’t keep asking humans – a.k.a. the engineers on our team – to go into an application and trigger the endpoints to expose data. That’s so much work.
Now on the surface, the automation looks easy to do. Hey, I’ll write out a couple of shell scripts, call API endpoints in a loop, and we should be good to go, right? Not exactly. There’s a couple of caveats and unknowns making this work challenging to execute. Let’s delve deeper and dive in 🙂 !
The Unknowns to Navigate
(A) When did an export need to be triggered? Was it after a scan’s completion? On each record – r1,…,rn – within a scan? Or on batches of records ( e.g. batches of 10,20, or 50 records )?
(B) When did data exports need to show up? Did they need to show up within five minutes? 24 hours? Or other configurable windows?
(C) How would we handle failed events or failed processing? Did we have ways to avoid duplicate work? Or can we allow duplicate events, if the code triggered for events is deterministic ( e.g. the output is the same for a given input )?
(D) What can we leverage to keep the design simple?
– Can we incorporate intermediate tables, Kafka queues/event buses, or long-running background daemons?
– Can we make changes to application-layer code or data-layer code? Can we leverage invariants of database triggers to confirm the completion of events – upstream and downstream?
(E) What design components are owned by our team, versus owned by other teams?
– Components owned by our team are faster to configure, customize, and develop.
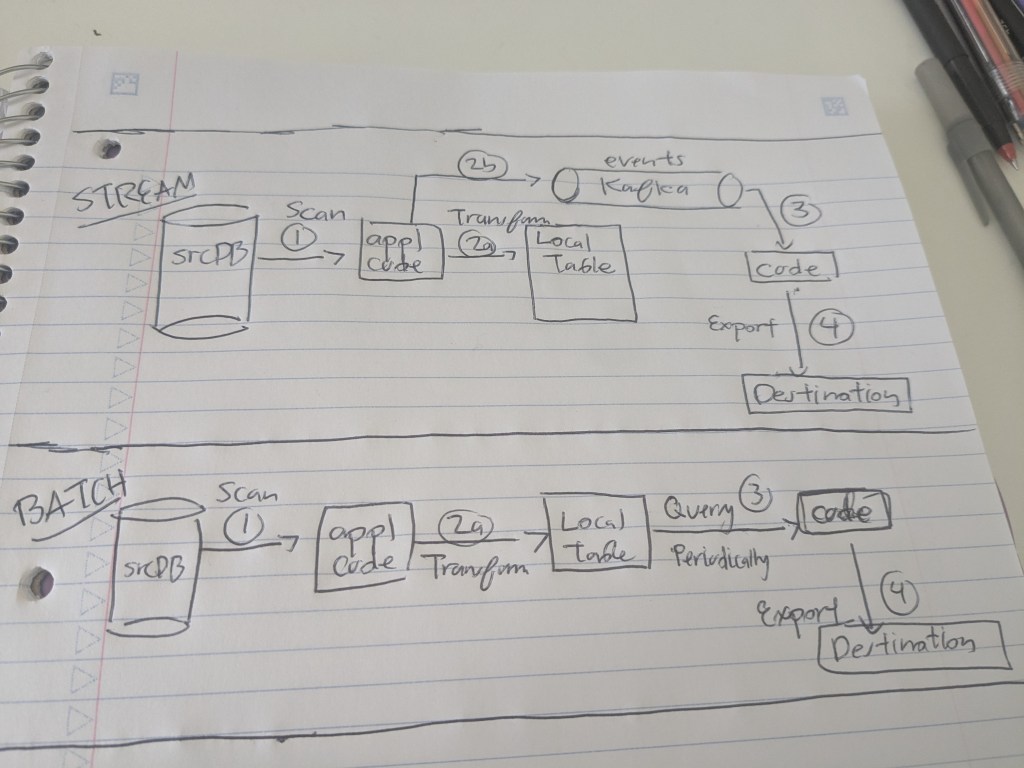
Scenario #1 : The Stream Mode
The true stream mode emulates a more event driven/CDC [ Change Data Capture ] idea, in which once a scanned record is written out to a database, some notion of an update having just occured needs to immediately trigger an export.
Before I started gathering requirements, I made the project more complex than it needed. I imagined in my hand that on each scan ( s_i ), I needed to trigger the export on the immediate storage of scan records ( r_1,r_2,…,r_n ). This means that at the smallest level of granularity, I needed to immediately export results to their intended destination. That meant introducing a notion of an event bus or CDC ( continuous data capture ) on each insert or update of a record into our local table.
Now while CDC or event-streaming is cool, it’s more complicated. The idea introduces additional steps and questions such as :
(A) Who should fire the event to inform that a record was stored? Whomst is the best authoritative source of truth? Should it be the producer ( the scanning application )? Or should we periodically poll the database?
(B) If we leverage events, how long should events persist?
(C) What do we do if a consuming application or daemon dies?
(D) Do we own Kafka queues or event-driven architectural components?
All of this introduces additional tasks and JIRA tickets. Like building out the Kafka queues or conducting a research & development story to find out if a local table has CDC capabilities. This delays the date of feature deliverability and adds long-term maintenance layers. More ever, it’s easy to get caught in the woods and introduce to many optimizations ( e.g. do we have to change the database storing our scanned results )? Optimization is good, BUT, over-optimizing a design is a “bad practice”.
What do we do instead?
… hmm, let’s try the batch mode.
Scenario #2 : The batch mode
The alternative solution involves batch operations. Instead of triggering an export on each record scanned, what if exports could be triggered on the completion of an entire scan? It turns out that a configurable time window for when the exports need to show up for our end users and a local database table enabled us to introduce the notion of time-bounded processing delay ( e.g. one hour or two hours ) before exporting results.
But how did we determine what to export? Did we conjure up criteria? Hmm – we have a local table of scan results with a flexible schema; we can introduce additional columns :
a. ScanExecutionFinished – Boolean flag ( TRUE = finished, FALSE = not finished )
b. ScanAlreadyExported – Boolean flag – ( TRUE = is exported, FALSE = not exported )
c. ScanExecutionStartTime – UNIX timestamp ( informs when a scan started )
d. ScanExecutionEndTime – UNIX timestamp ( informs when a scan ended )
We can leverage the four columns to enable a FIFO-esque automated processing of scans and exports ; exports should auto-trigger for scans with earlier execution times than those with later execution times. A cutoff time window ( e.g. a timestamp value ) can be used – let us denote this as T_prime
If all three conditions are met for a given scan :
a. ScanExecutionEndTime <= T_prime
b. ScanExecutionFinished=True
c. scanAlreadyExported = False
Trigger an export and set scanAlreadyExported = True
Else, do not trigger an export.
As for how to do the batch processing, that’s up to the engineering team. I won’t delve to deep here, but I’ll briefly touch upon the two big ones –
(A) Utilize Airflow DAGS to trigger endpoints
(B) Introduce periodic consumer-side polling of database tables.
My Biggest Takeaways
I learned a lot from this experience in designing systems – lemme share them!
- Requirements Gathering – Focus on the gathering of the requirements! . Don’t just dive in. Set up meetings with other engineers and understand the overall ask at hand.
- Build Simpler – Streaming is cool and we say that’s the future of the world. But if we’re operating in an unconstrained environment and need to ship faster, why not build simpler? Let’s bias to batch processing if we can!
- What’s under your control – Identify your locus of control – interior and exterior. Ask what’s under your control and what’s not under your control? In our case, we had control over the following :
(A) The time window of exports showing up
(B) The handling of duplicate events
(C) The components we could introduce and own ( e.g. local PostgreDB tables or Kafka queues ) - Conjure criteria sets and conditions – Can we determine a rules engine – or set of criteria – to determine when to execute an operation? Let’s imagine we built from the perspective of a grossly-simplified data structures & algorithms problem?

Leave a comment