
Sometimes you gotta write fake data – or make up things that are close to real – in order to get things working.
Fake it till you make it!
Replay the scenario! What happens!
Junior TDP engineer, Lolo, needs to write up unit tests and integration/end-to-end tests on a feature release, and in order to do so, has to acquire data from enterprises databases as her inputs. But Lo ( lo ) and behold, she’s unable to ; she’s facing a MAJOR BLOCKER! She can’t access her workplace’s PostgreDB instances. Lolo thinks the task is undoable, but wait, we’re software engineers, and we need to conjure and think about workarounds when faced with constraints. Lolo goes to her senior engineer, Arturo, who leverages the past experiences and the intuitions of himself and his other senior engineers, to set feature direction.
Arturo collaborates with other engineers, weighs the pros and cons of decision making, and identifies the best solution across a set of multiple outcome paths, with pros and cons for each path :
- Feature/Test partitioning – Can we identify and partition tests into those dependent on database data versus those independent? Most unit tests can be written without a database dependency – it’s only regression tests or end-to-end tests that need them
Pro : Splits up and decomposes tasks into independently executable, delegable units of work.
Con : At some point, we’ll still run back to the same access issues. - Use other data sources – Database one ( PostgresDB ) is unavailable for access, but what about the other database platforms? My application accesses other tables from SnowflakeDB, SqlServer, and DynamoDB, Can I leverage one of the other databases to meet testing needs?
Pros :
(A) If one of these sources is unavailable, it bypasses access request or connection difficulty issues
Cons :
(A) Assumptions that other sources are available
(B) inability to verify if application will work in production for all edge cases - Mock Data injection – We own PostgreDB instances – can we write scripts and inject mock data? Can we mock data at database tier or application tier, if a database is unavailable?
Pros : Listed below!
Cons : We can’t assert that our code works with actual production or non-production databases. - Reprioritze feature development – maybe we can shift development focus elsewhere and wait for database access requests.
Pros : Development effort is shifted elsewhere.
Cons : Developers need to context switch from current task to other tasks. Access requests can take business days to resolve.
How mocking data saves us! The benefits!
- Avoid failure modes – if we need a database for testing, that means we need to assume we have the following
a. AuthN and AuthZ : Authentication and Authorization
b. Working machines . A database is a server or installed on a server.
c. Network connectivity between machine and database
d. Working database . A recent upgrade patch or competing processes could entail a failing database
The failure mode list is comprehensive, but if we create mocks, we avoid all of the above; this saves on debug time and team discussion time. - Expedited developer velocity – mocking the data might entail half-an-hour to one-hour of work, but the time savings in not waiting on external third parties to get access or failure mode resolution means the ability to get back to focusing on change lists.
- Ease of sharing and customization – mock data creation scripts can be inserted at application layer and customized according to environments. Other engineers can add, delete, or update the mock data for needs elsewhere.
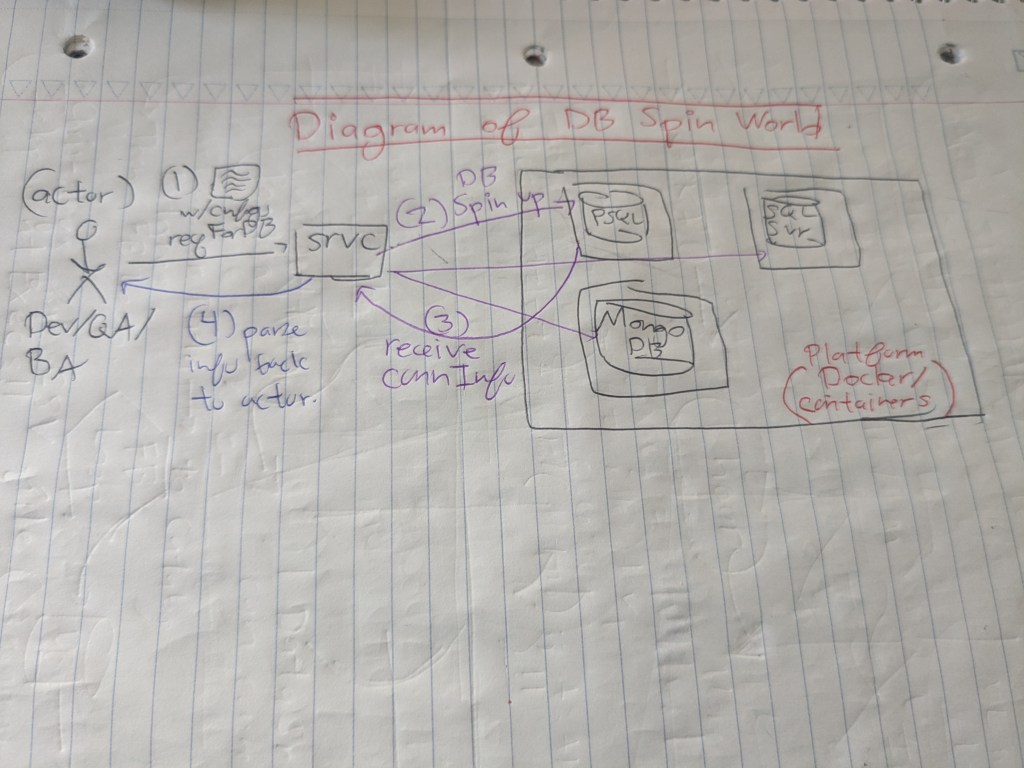
DB Spin – the real-world ideal scenario?
Containerization – if I can’t access a machine, what if I make my own world up? I can leverage containers and technologies ( e.g. Docker or K8S ) to rapidly spin up and tear down resources. I just need a docker file, a database, and a mock script and BOOM, a testable input!
Maybe in the future, a start-up or a major company can built a product for spinning up databases quickly on the fly. Imagine an engineer wanted to verbally describe – or pro-gramatically describe – how to set up a mock database. They could quickly spin up databases of different configurations ( platform, version, memory, disk ) and specify tables with records of information. They could spin up multiple databases on this application ( e.g. 5 databases ) and basic network configurations for development or testing purposes.
It’d take a few months to a year to build out the MVP of the product, but it can save developers on costs and feature development time spent. K8S, Docker, or other container/orchestration technologies offer the capability, BUT, not in the most user-friendly way.
The impacts of a product could be useful, not only in one company, but several? I’d imagine quick database testing products to be useful at organizational levels.
Footnotes
- This post was inspired by a real-world engineering scenario and the technical discussions that happened in a previous company.

Leave a comment