
A Primer
Freshly-minted, awe-inspired, recently matriculated from his undergraduate college, Alejandro, enters the workforce; he’s stunned at the level of complexity that he notices in the systems and infrastructure undergirding big tech. Inspired by a sense of interest, curiosity, and his volition, he spends some time diving deep into common system patterns and notices a recurring theme, which I’ll term as centralization. Whether it’s an OLAP database – purposed for analytical queries – acting as a sink to OLTP data sources, a central layer interfacing across multiple vendors that come in and come out, or a centralized logger to track requests across different machines and databases – centralization remains here to stay. The architectural pattern – fundamentally intrinsic to the DNA of big tech companies – will continue to persist.
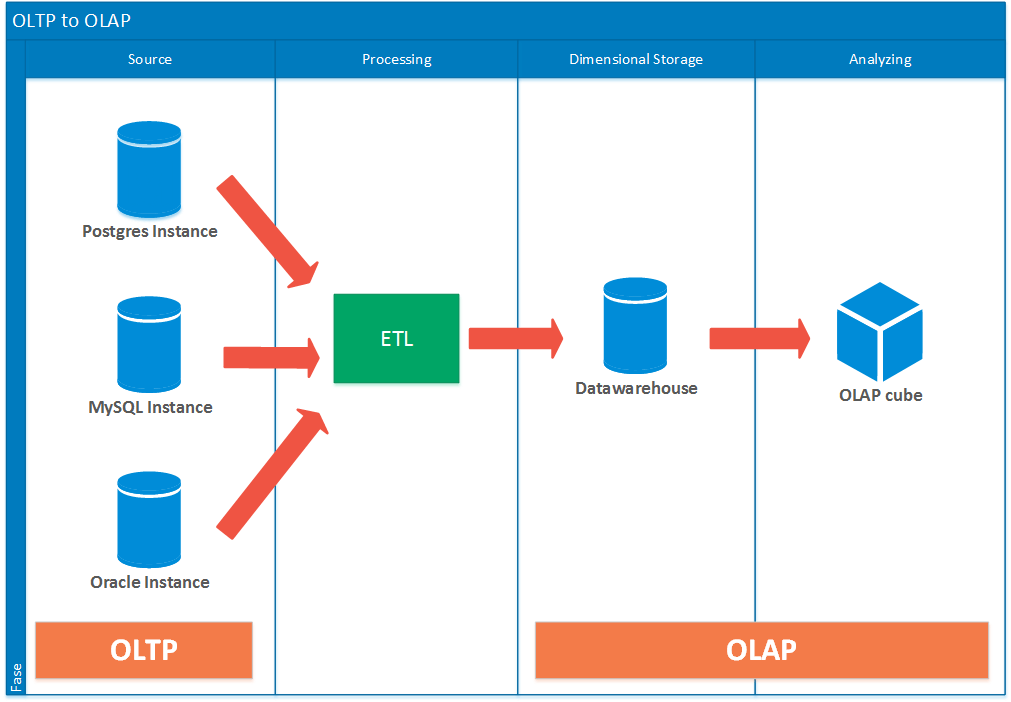
OLAP Database Sink for OLTP Database Sources
Frequently across companies, you’ll encounter multiple enterprise web applications or internal-facing applications leveraging transactional databases. These databases span vendors – PostgresDB, MySQL, SqlServer, and Amazon DynamoDB, for example. In order to centralize the location of all this data into one common, easily-accessible location, data engineers and software developers will set up ETL pipelines to execute Extract, Transform, and Load Operations on the data chain. The flow of data follows from source OLTP Database -> Extract -> Transform -> Load -> sink OLAP Data warehouse. A major benefit with OLAP Datawarehouses is the dimensional storage capability – with data and relationships built atop Star and Snowflake schemas I won’t dive to much here. Additionally, OLAP Datawarehousing enables the OLAP cube capability – serving as a caching tier for frequently executed analytical queries. The OLAP Cube proves its usefulness for critical, high-revenue paying customers.
Centralized Logging – Tracking Requests and Responses across Machines and Databases
#TODO
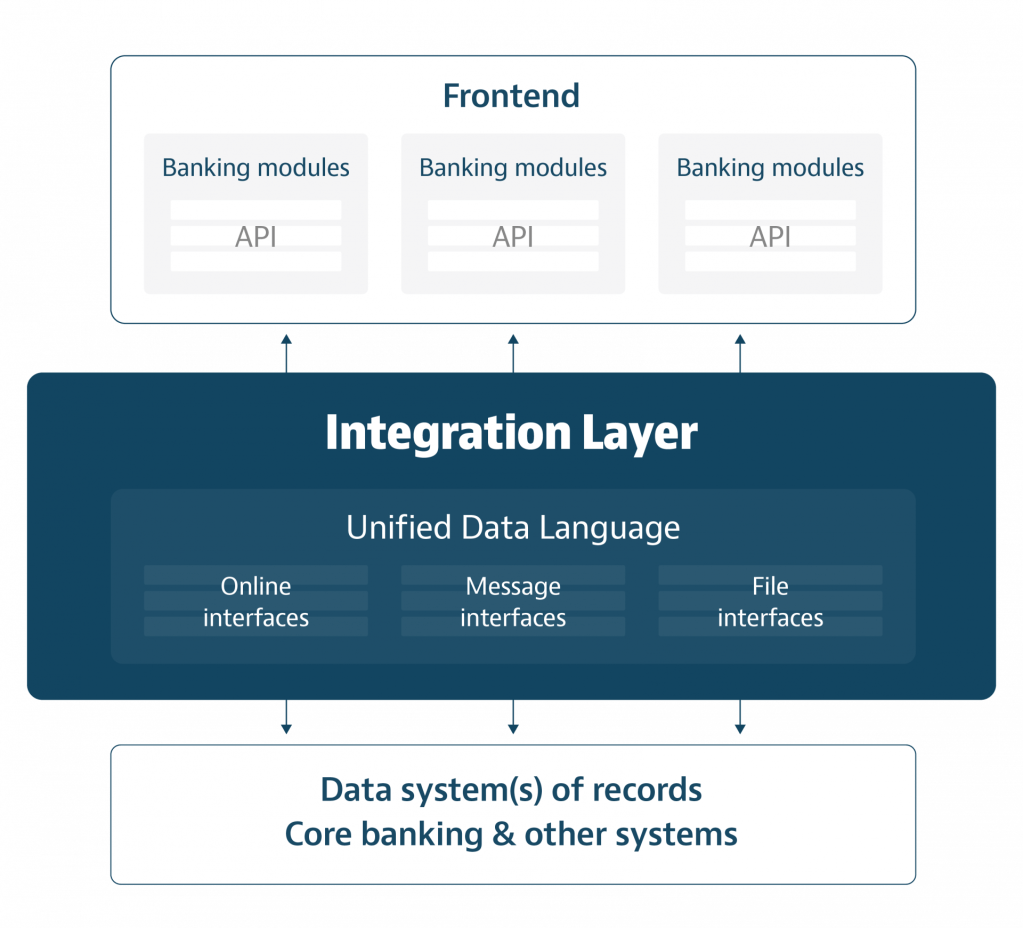
Centralized Integration Layer – interface with multiple vendors and Enterprise systems; build long-term
Alright third example of centralization. And probably by favorite. Also sometimes called an Integrational Layer. This architectural design pattern shares similarities with the OLTP-OLAP model, but there’s a minor difference with respect to the level of customization. OLTP to OLAP models tend to leverage already existing OLAP offerings ( e.g. Snowflake, Amazon Aurora, Google Big Query ). However, an Integration Layer is it’s own stand-alone “database esque” layer with custom application layer logic built atop. In this layer, data is either (A) collected and stored in an OLAP-esque style via Enterprise ETL pipelines or (B) queried via user-friedly interfaces or APIs. Whether or not an integration layer has its own data query language is up to the collaboration of engineering talent, internal stakeholders, and enterprise requirements.
Benefits of Integration Layer
1. Avoid vendor lock-in : using a single data source means being limited to the query capabilities offered by a single vendor. Built-in query capabilities may lack in complexity or ability to address ambiguous, unexpected business needs.
2. Integrate as vendors evolve over time : centralization engenders the ability to add or remove data sources on a “plug-and-play” basis. If a technology needs to be sunsetted for Enterprise reasons ( e.g. the original provider no longer supports a soon-to-be-deprecated version or security mandates disallow usage of a given solution )
3. Builds across business needs : Different business needs naturally entail unique data solutions. Some business needs lend themselves to SQL Server, some to to NoSQL Document stores, and others to Vector databases ( for modern day Generative AI ). A central layer storing all data means that multiple customers can access Enterprise data – spanning multiple locations – in one single authoritative location.
Drawbacks of Integration Layer :
1. Must build own query logic : The layers are custom-built, meaning that enterprise-side developers will need to either (a) build off atop existing query mechanisms or (b) create their own DQL ( Data Query Language ) to interact with the stored data.
2. Involves build out time : A centralized layer can take a few quarters to build out, so as not to break existing applications relying on individual databases or subsets of databases.

Leave a comment